19 KiB
2.2 Go基礎
這小節我們將要介紹如何定義變數、常量、Go內建型別以及Go程式設計中的一些技巧。
定義變數
Go語言裡面定義變數有多種方式。
使用var關鍵字是Go最基本的定義變數方式,與C語言不同的是Go把變數型別放在變數名後面:
//定義一個名稱為“variableName”,型別為"type"的變數
var variableName type
定義多個變數
//定義三個型別都是“type”的變數
var vname1, vname2, vname3 type
定義變數並初始化值
//初始化“variableName”的變數為“value”值,型別是“type”
var variableName type = value
同時初始化多個變數
/*
定義三個型別都是"type"的變數,並且分別初始化為相應的值
vname1為v1,vname2為v2,vname3為v3
*/
var vname1, vname2, vname3 type= v1, v2, v3
你是不是覺得上面這樣的定義有點繁瑣?沒關係,因為Go語言的設計者也發現了,有一種寫法可以讓它變得簡單一點。我們可以直接忽略型別宣告,那麼上面的程式碼變成這樣了:
/*
定義三個變數,它們分別初始化為相應的值
vname1為v1,vname2為v2,vname3為v3
然後Go會根據其相應值的型別來幫你初始化它們
*/
var vname1, vname2, vname3 = v1, v2, v3
你覺得上面的還是有些繁瑣?好吧,我也覺得。讓我們繼續簡化:
/*
定義三個變數,它們分別初始化為相應的值
vname1為v1,vname2為v2,vname3為v3
編譯器會根據初始化的值自動推匯出相應的型別
*/
vname1, vname2, vname3 := v1, v2, v3
現在是不是看上去非常簡潔了?:=這個符號直接取代了var和type,這種形式叫做簡短宣告。不過它有一個限制,那就是它只能用在函式內部;在函式外部使用則會無法編譯透過,所以一般用var方式來定義全域性變數。
_(下劃線)是個特殊的變數名,任何賦予它的值都會被丟棄。在這個例子中,我們將值35賦予b,並同時丟棄34:
_, b := 34, 35
Go對於已宣告但未使用的變數會在編譯階段報錯,比如下面的程式碼就會產生一個錯誤:聲明瞭i但未使用。
package main
func main() {
var i int
}
常量
所謂常量,也就是在程式編譯階段就確定下來的值,而程式在執行時無法改變該值。在Go程式中,常量可定義為數值、布林值或字串等型別。
它的語法如下:
const constantName = value
//如果需要,也可以明確指定常量的型別:
const Pi float32 = 3.1415926
下面是一些常量宣告的例子:
const Pi = 3.1415926
const i = 10000
const MaxThread = 10
const prefix = "astaxie_"
Go 常量和一般程式語言不同的是,可以指定相當多的小數位數(例如200位), 若指定給float32自動縮短為32bit,指定給float64自動縮短為64bit,詳情參考連結
內建基礎型別
Boolean
在Go中,布林值的型別為bool,值是true或false,預設為false。
//示例程式碼
var isActive bool // 全域性變數宣告
var enabled, disabled = true, false // 忽略型別的宣告
func test() {
var available bool // 一般宣告
valid := false // 簡短宣告
available = true // 賦值操作
}
數值型別
整數型別有無符號和帶符號兩種。Go同時支援int和uint,這兩種型別的長度相同,但具體長度取決於不同編譯器的實現。Go裡面也有直接定義好位數的型別:rune, int8, int16, int32, int64和byte, uint8, uint16, uint32, uint64。其中rune是int32的別稱,byte是uint8的別稱。
需要注意的一點是,這些型別的變數之間不允許互相賦值或操作,不然會在編譯時引起編譯器報錯。
如下的程式碼會產生錯誤:invalid operation: a + b (mismatched types int8 and int32)
var a int8
var b int32
c:=a + b
另外,儘管int的長度是32 bit, 但int 與 int32並不可以互用。
浮點數的型別有float32和float64兩種(沒有float型別),預設是float64。
這就是全部嗎?No!Go還支援複數。它的預設型別是complex128(64位實數+64位虛數)。如果需要小一些的,也有complex64(32位實數+32位虛數)。複數的形式為RE + IMi,其中RE是實數部分,IM是虛數部分,而最後的i是虛數單位。下面是一個使用複數的例子:
var c complex64 = 5+5i
//output: (5+5i)
fmt.Printf("Value is: %v", c)
字串
我們在上一節中講過,Go中的字串都是採用UTF-8字符集編碼。字串是用一對雙引號("")或反引號(` `)括起來定義,它的型別是string。
//示例程式碼
var frenchHello string // 宣告變數為字串的一般方法
var emptyString string = "" // 聲明瞭一個字串變數,初始化為空字串
func test() {
no, yes, maybe := "no", "yes", "maybe" // 簡短宣告,同時宣告多個變數
japaneseHello := "Konichiwa" // 同上
frenchHello = "Bonjour" // 常規賦值
}
在Go中字串是不可變的,例如下面的程式碼編譯時會報錯:cannot assign to s[0]
var s string = "hello"
s[0] = 'c'
但如果真的想要修改怎麼辦呢?下面的程式碼可以實現:
s := "hello"
c := []byte(s) // 將字串 s 轉換為 []byte 型別
c[0] = 'c'
s2 := string(c) // 再轉換回 string 型別
fmt.Printf("%s\n", s2)
Go中可以使用+運算子來連線兩個字串:
s := "hello,"
m := " world"
a := s + m
fmt.Printf("%s\n", a)
修改字串也可寫為:
s := "hello"
s = "c" + s[1:] // 字串雖不能更改,但可進行切片操作
fmt.Printf("%s\n", s)
如果要宣告一個多行的字串怎麼辦?可以透過`來宣告:
m := `hello
world`
` 括起的字串為Raw字串,即字串在程式碼中的形式就是列印時的形式,它沒有字元轉義,換行也將原樣輸出。例如本例中會輸出:
hello
world
錯誤型別
Go內建有一個error型別,專門用來處理錯誤資訊,Go的package裡面還專門有一個套件errors來處理錯誤:
err := errors.New("emit macho dwarf: elf header corrupted")
if err != nil {
fmt.Print(err)
}
Go資料底層的儲存
下面這張圖來源於Russ Cox Blog中一篇介紹Go資料結構的文章,大家可以看到這些基礎型別底層都是分配了一塊記憶體,然後儲存了相應的值。

圖2.1 Go資料格式的儲存
一些技巧
分組宣告
在Go語言中,同時宣告多個常量、變數,或者匯入多個套件時,可採用分組的方式進行宣告。
例如下面的程式碼:
import "fmt"
import "os"
const i = 100
const pi = 3.1415
const prefix = "Go_"
var i int
var pi float32
var prefix string
可以分組寫成如下形式:
import(
"fmt"
"os"
)
const(
i = 100
pi = 3.1415
prefix = "Go_"
)
var(
i int
pi float32
prefix string
)
iota列舉
Go裡面有一個關鍵字iota,這個關鍵字用來宣告enum的時候採用,它預設開始值是0,const中每增加一行加1:
package main
import (
"fmt"
)
const (
x = iota // x == 0
y = iota // y == 1
z = iota // z == 2
w // 常量宣告省略值時,預設和之前一個值的字面相同。這裡隱式地說w = iota,因此w == 3。其實上面y和z可同樣不用"= iota"
)
const v = iota // 每遇到一個const關鍵字,iota就會重置,此時v == 0
const (
h, i, j = iota, iota, iota //h=0,i=0,j=0 iota在同一行值相同
)
const (
a = iota //a=0
b = "B"
c = iota //c=2
d, e, f = iota, iota, iota //d=3,e=3,f=3
g = iota //g = 4
)
func main() {
fmt.Println(a, b, c, d, e, f, g, h, i, j, x, y, z, w, v)
}
除非被顯式設定為其它值或
iota,每個const分組的第一個常量被預設設定為它的0值,第二及後續的常量被預設設定為它前面那個常量的值,如果前面那個常量的值是iota,則它也被設定為iota。
Go程式設計的一些規則
Go之所以會那麼簡潔,是因為它有一些預設的行為:
- 大寫字母開頭的變數是可匯出的,也就是其它套件可以讀取的,是公有變數;小寫字母開頭的就是不可匯出的,是私有變數。
- 大寫字母開頭的函式也是一樣,相當於
class中的帶public關鍵詞的公有函式;小寫字母開頭的就是有private關鍵詞的私有函式。
array、slice、map
array
array就是陣列,它的定義方式如下:
var arr [n]type
在[n]type中,n表示陣列的長度,type表示儲存元素的型別。對陣列的操作和其它語言類似,都是透過[]來進行讀取或賦值:
var arr [10]int // 聲明瞭一個int型別的陣列
arr[0] = 42 // 陣列下標是從0開始的
arr[1] = 13 // 賦值操作
fmt.Printf("The first element is %d\n", arr[0]) // 取得資料,返回42
fmt.Printf("The last element is %d\n", arr[9]) //返回未賦值的最後一個元素,預設返回0
由於長度也是陣列型別的一部分,因此[3]int與[4]int是不同的型別,陣列也就不能改變長度。陣列之間的賦值是值的賦值,即當把一個數組作為引數傳入函式的時候,傳入的其實是該陣列的副本,而不是它的指標。如果要使用指標,那麼就需要用到後面介紹的slice型別了。
陣列可以使用另一種:=來宣告
a := [3]int{1, 2, 3} // 聲明瞭一個長度為3的int陣列
b := [10]int{1, 2, 3} // 聲明瞭一個長度為10的int陣列,其中前三個元素初始化為1、2、3,其它預設為0
c := [...]int{4, 5, 6} // 可以省略長度而採用`...`的方式,Go會自動根據元素個數來計算長度
也許你會說,我想數組裡面的值還是陣列,能實現嗎?當然咯,Go支援巢狀陣列,即多維陣列。比如下面的程式碼就聲明瞭一個二維陣列:
// 聲明瞭一個二維陣列,該陣列以兩個陣列作為元素,其中每個陣列中又有4個int型別的元素
doubleArray := [2][4]int{[4]int{1, 2, 3, 4}, [4]int{5, 6, 7, 8}}
// 上面的宣告可以簡化,直接忽略內部的型別
easyArray := [2][4]int{{1, 2, 3, 4}, {5, 6, 7, 8}}
陣列的分配如下所示:
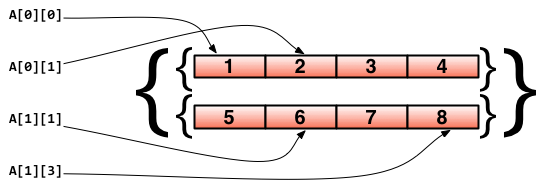
圖2.2 多維陣列的對映關係
slice
在很多應用場景中,陣列並不能滿足我們的需求。在初始定義陣列時,我們並不知道需要多大的陣列,因此我們就需要“動態陣列”。在Go裡面這種資料結構叫slice
slice並不是真正意義上的動態陣列,而是一個參考型別。slice總是指向一個底層array,slice的宣告也可以像array一樣,只是不需要長度。
// 和宣告array一樣,只是少了長度
var fslice []int
接下來我們可以宣告一個slice,並初始化資料,如下所示:
slice := []byte {'a', 'b', 'c', 'd'}
slice可以從一個數組或一個已經存在的slice中再次宣告。slice透過array[i:j]來取得,其中i是陣列的開始位置,j是結束位置,但不包含array[j],它的長度是j-i。
// 宣告一個含有10個元素元素型別為byte的陣列
var ar = [10]byte {'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'}
// 宣告兩個含有byte的slice
var a, b []byte
// a指向陣列的第3個元素開始,併到第五個元素結束,
a = ar[2:5]
//現在a含有的元素: ar[2]、ar[3]和ar[4]
// b是陣列ar的另一個slice
b = ar[3:5]
// b的元素是:ar[3]和ar[4]
注意
slice和陣列在宣告時的區別:宣告陣列時,方括號內寫明瞭陣列的長度或使用...自動計算長度,而宣告slice時,方括號內沒有任何字元。
它們的資料結構如下所示

圖2.3 slice和array的對應關係圖
slice有一些簡便的操作
slice的預設開始位置是0,ar[:n]等價於ar[0:n]slice的第二個序列預設是陣列的長度,ar[n:]等價於ar[n:len(ar)]- 如果從一個數組裡面直接取得
slice,可以這樣ar[:],因為預設第一個序列是0,第二個是陣列的長度,即等價於ar[0:len(ar)]
下面這個例子展示了更多關於slice的操作:
// 宣告一個數組
var array = [10]byte{'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'}
// 宣告兩個slice
var aSlice, bSlice []byte
// 示範一些簡便操作
aSlice = array[:3] // 等價於aSlice = array[0:3] aSlice包含元素: a,b,c
aSlice = array[5:] // 等價於aSlice = array[5:10] aSlice包含元素: f,g,h,i,j
aSlice = array[:] // 等價於aSlice = array[0:10] 這樣aSlice包含了全部的元素
// 從slice中取得slice
aSlice = array[3:7] // aSlice包含元素: d,e,f,g,len=4,cap=7
bSlice = aSlice[1:3] // bSlice 包含aSlice[1], aSlice[2] 也就是含有: e,f
bSlice = aSlice[:3] // bSlice 包含 aSlice[0], aSlice[1], aSlice[2] 也就是含有: d,e,f
bSlice = aSlice[0:5] // 對slice的slice可以在cap範圍內擴充套件,此時bSlice包含:d,e,f,g,h
bSlice = aSlice[:] // bSlice包含所有aSlice的元素: d,e,f,g
slice是參考型別,所以當參考改變其中元素的值時,其它的所有參考都會改變該值,例如上面的aSlice和bSlice,如果修改了aSlice中元素的值,那麼bSlice相對應的值也會改變。
從概念上面來說slice像一個結構體,這個結構體包含了三個元素:
- 一個指標,指向陣列中
slice指定的開始位置 - 長度,即
slice的長度 - 最大長度,也就是
slice開始位置到陣列的最後位置的長度
Array_a := [10]byte{'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'}
Slice_a := Array_a[2:5]
上面程式碼的真正儲存結構如下圖所示

圖2.4 slice對應陣列的資訊
對於slice有幾個有用的內建函式:
len取得slice的長度cap取得slice的最大容量append向slice裡面追加一個或者多個元素,然後返回一個和slice一樣型別的slicecopy函式copy從源slice的src中複製元素到目標dst,並且返回複製的元素的個數
注:append函式會改變slice所參考的陣列的內容,從而影響到參考同一陣列的其它slice。
但當slice中沒有剩餘空間(即(cap-len) == 0)時,此時將動態分配新的陣列空間。返回的slice陣列指標將指向這個空間,而原陣列的內容將保持不變;其它參考此陣列的slice則不受影響。
從Go1.2開始slice支援了三個引數的slice,之前我們一直採用這種方式在slice或者array基礎上來取得一個slice
var array [10]int
slice := array[2:4]
這個例子裡面slice的容量是8,新版本里面可以指定這個容量
slice = array[2:4:7]
上面這個的容量就是7-2,即5。這樣這個產生的新的slice就沒辦法訪問最後的三個元素。
如果slice是這樣的形式array[:i:j],即第一個引數為空,預設值就是0。
map
map也就是Python中字典的概念,它的格式為map[keyType]valueType
我們看下面的程式碼,map的讀取和設定也類似slice一樣,透過key來操作,只是slice的index只能是`int`型別,而map多了很多型別,可以是int,可以是string及所有完全定義了==與!=操作的型別。
// 宣告一個key是字串,值為int的字典,這種方式的宣告需要在使用之前使用make初始化
var numbers map[string]int
// 另一種map的宣告方式
numbers = make(map[string]int)
numbers["one"] = 1 //賦值
numbers["ten"] = 10 //賦值
numbers["three"] = 3
fmt.Println("第三個數字是: ", numbers["three"]) // 讀取資料
// 打印出來如:第三個數字是: 3
這個map就像我們平常看到的表格一樣,左邊列是key,右邊列是值
使用map過程中需要注意的幾點:
map是無序的,每次打印出來的map都會不一樣,它不能透過index取得,而必須透過key取得map的長度是不固定的,也就是和slice一樣,也是一種參考型別- 內建的
len函式同樣適用於map,返回map擁有的key的數量 map的值可以很方便的修改,透過numbers["one"]=11可以很容易的把key為one的字典值改為11map和其他基本型別不同,它不是thread-safe,在多個go-routine存取時,必須使用mutex lock機制
map的初始化可以透過key:val的方式初始化值,同時map內建有判斷是否存在key的方式
透過delete刪除map的元素:
// 初始化一個字典
rating := map[string]float32{"C":5, "Go":4.5, "Python":4.5, "C++":2 }
// map有兩個返回值,第二個返回值,如果不存在key,那麼ok為false,如果存在ok為true
csharpRating, ok := rating["C#"]
if ok {
fmt.Println("C# is in the map and its rating is ", csharpRating)
} else {
fmt.Println("We have no rating associated with C# in the map")
}
delete(rating, "C") // 刪除key為C的元素
上面說過了,map也是一種參考型別,如果兩個map同時指向一個底層,那麼一個改變,另一個也相應的改變:
m := make(map[string]string)
m["Hello"] = "Bonjour"
m1 := m
m1["Hello"] = "Salut" // 現在m["hello"]的值已經是Salut了
make、new操作
make用於內建型別(map、slice 和channel)的記憶體分配。new用於各種型別的記憶體分配。
內建函式new本質上說跟其它語言中的同名函式功能一樣:new(T)分配了零值填充的T型別的記憶體空間,並且返回其地址,即一個*T型別的值。用Go的術語說,它返回了一個指標,指向新分配的型別T的零值。有一點非常重要:
new返回指標。
內建函式make(T, args)與new(T)有著不同的功能,make只能建立slice、map和channel,並且返回一個有初始值(非零)的T型別,而不是*T。本質來講,導致這三個型別有所不同的原因是指向資料結構的參考在使用前必須被初始化。例如,一個slice,是一個包含指向資料(內部array)的指標、長度和容量的三項描述符;在這些專案被初始化之前,slice為nil。對於slice、map和channel來說,make初始化了內部的資料結構,填充適當的值。
make返回初始化後的(非零)值。
下面這個圖詳細的解釋了new和make之間的區別。

圖2.5 make和new對應底層的記憶體分配
零值
關於“零值”,所指並非是空值,而是一種“變數未填充前”的預設值,通常為0。 此處羅列 部分類型 的 “零值”
int 0
int8 0
int32 0
int64 0
uint 0x0
rune 0 //rune的實際型別是 int32
byte 0x0 // byte的實際型別是 uint8
float32 0 //長度為 4 byte
float64 0 //長度為 8 byte
bool false
string ""