517 lines
19 KiB
Markdown
517 lines
19 KiB
Markdown
# 2.3 Declarações de controle e funções
|
||
|
||
Nesta seção nós vamos falar sobre declarações de controle e operações de funções em Go.
|
||
|
||
## Declarações de Controle
|
||
|
||
A maior invenção na programação é o controle de fluxo. Por causa dele, você é capaz de utilizar declarações de controle simples que podem ser usadas para representar lógicas complexas. Existem três categorias de controle de fluxo: condicional, controle de ciclo e salto incondicional.
|
||
|
||
### if
|
||
|
||
`if` provavelmente será a palavra-chave mais utilizada nos seus programas. Se ele atende as condições, então ele faz alguma coisa e caso contrário faz alguma outra coisa.
|
||
|
||
`if` não precisa de parênteses em Go.
|
||
|
||
if x > 10 {
|
||
fmt.Println("x is greater than 10")
|
||
} else {
|
||
fmt.Println("x is less than or equal to 10")
|
||
}
|
||
|
||
A coisa mais útil sobre o `if` em Go é que ele pode ter uma instrução de inicialização antes da instrução condicional. O escopo das variáveis definidas nesta instrução de inicialização só estão disponíveis dentro do bloco de definição do `if`.
|
||
|
||
// inicializa x e então confere se x é maior que 10
|
||
if x := computedValue(); x > 10 {
|
||
fmt.Println("x is greater than 10")
|
||
} else {
|
||
fmt.Println("x is less than 10")
|
||
}
|
||
|
||
// o código seguinte não compilará
|
||
fmt.Println(x)
|
||
|
||
Use if-else para múltiplas condições.
|
||
|
||
if integer == 3 {
|
||
fmt.Println("The integer is equal to 3")
|
||
} else if integer < 3 {
|
||
fmt.Println("The integer is less than 3")
|
||
} else {
|
||
fmt.Println("The integer is greater than 3")
|
||
}
|
||
|
||
### goto
|
||
|
||
Go possui uma palavra-chave chamada `goto`, mas cuidado ao utilizar ela. `goto` reencaminha o fluxo de controle para um `label` definido anteriormente dentro do mesmo bloco de código.
|
||
|
||
func myFunc() {
|
||
i := 0
|
||
Here: // label termina com ":"
|
||
fmt.Println(i)
|
||
i++
|
||
goto Here // pule para o label "Here"
|
||
}
|
||
|
||
O nome do label é case sensitive.
|
||
|
||
### for
|
||
|
||
`for` é a lógica de controle mais poderosa em Go. Ele pode ler dados em loops e operações iterativas, assim como o `while`.
|
||
|
||
for expression1; expression2; expression3 {
|
||
//...
|
||
}
|
||
|
||
`expression1`, `expression2` e `expression3` são todas expressões, onde `expression1` e `expression3` são definições de variáveis ou atribuições, e `expression2` é uma declaração condicional. `expression1` será executada uma vez antes do loop, e `expression3` será executada depois de cada iteração do loop.
|
||
|
||
Exemplos são mais úteis que palavras.
|
||
|
||
package main
|
||
import "fmt"
|
||
|
||
func main(){
|
||
sum := 0;
|
||
for index:=0; index < 10 ; index++ {
|
||
sum += index
|
||
}
|
||
fmt.Println("sum is equal to ", sum)
|
||
}
|
||
// Mostra: sum is equal to 45
|
||
|
||
Algumas vezes nós precisamos de várias atribuições, porém Go não possui o operador `,`, então nós usamos atribuições paralelas como `i, j = i + 1, j - 1`.
|
||
|
||
Nós podemos omitir as expressões `expression1` e `expression3` se elas não forem necessárias.
|
||
|
||
sum := 1
|
||
for ; sum < 1000; {
|
||
sum += sum
|
||
}
|
||
|
||
Podemos omitir também o `;`. Isto lhe parece familiar? Sim, é idêntico ao `while`.
|
||
|
||
sum := 1
|
||
for sum < 1000 {
|
||
sum += sum
|
||
}
|
||
|
||
Existem duas operações importantes em loops que são `break` e `continue`. `break` "pula" fora do loop, e `continue` ignora o loop atual e inicia o próximo. Se você tiver loops aninhados use `break` juntamente com labels.
|
||
|
||
for index := 10; index>0; index-- {
|
||
if index == 5{
|
||
break // ou continue
|
||
}
|
||
fmt.Println(index)
|
||
}
|
||
// break mostra 10、9、8、7、6
|
||
// continue mostra 10、9、8、7、6、4、3、2、1
|
||
|
||
`for` pode ler dados de um `slice` ou `map` quando for utilizado junto com `range`.
|
||
|
||
for k,v:=range map {
|
||
fmt.Println("map's key:",k)
|
||
fmt.Println("map's val:",v)
|
||
}
|
||
|
||
Como Go suporta múltiplos valores de retorno e gera um erro de compilação caso você não use os valores que foram definidos, você pode querer utilizar `_` para descartar certos valores de retorno.
|
||
|
||
for _, v := range map{
|
||
fmt.Println("map's val:", v)
|
||
}
|
||
|
||
### switch
|
||
|
||
As vezes você pode achar que está usando muitas instruções `if-else` para implementar uma lógica, o que pode dificultar a leitura e manutenção no futuro. Este é o momento perfeito para utilizar a instrução `switch` para resolver este problema.
|
||
|
||
switch sExpr {
|
||
case expr1:
|
||
some instructions
|
||
case expr2:
|
||
some other instructions
|
||
case expr3:
|
||
some other instructions
|
||
default:
|
||
other code
|
||
}
|
||
|
||
Os tipos de `sExpr`, `expr1`, `expr2`, e `expr3` devem ser o mesmo. `switch` é muito flexível. As condições não precisam ser constantes e são executadas de cima para baixo até que encontre uma condição válida. Se não houver nenhuma instrução após a palavra-chave `switch`, então ela corresponderá a `true`.
|
||
|
||
i := 10
|
||
switch i {
|
||
case 1:
|
||
fmt.Println("i is equal to 1")
|
||
case 2, 3, 4:
|
||
fmt.Println("i is equal to 2, 3 or 4")
|
||
case 10:
|
||
fmt.Println("i is equal to 10")
|
||
default:
|
||
fmt.Println("All I know is that i is an integer")
|
||
}
|
||
|
||
Na quinta linha, colocamos vários valores em um `case`, e não precisamos adicionar a palavra-chave `break` no final do bloco do `case`. Ele irá sair do bloco do switch quando encontrar uma condição verdadeira. Se você deseja continuar verificando mais casos, você precisará utilizar a instrução `fallthrough`.
|
||
|
||
integer := 6
|
||
switch integer {
|
||
case 4:
|
||
fmt.Println("integer <= 4")
|
||
fallthrough
|
||
case 5:
|
||
fmt.Println("integer <= 5")
|
||
fallthrough
|
||
case 6:
|
||
fmt.Println("integer <= 6")
|
||
fallthrough
|
||
case 7:
|
||
fmt.Println("integer <= 7")
|
||
fallthrough
|
||
case 8:
|
||
fmt.Println("integer <= 8")
|
||
fallthrough
|
||
default:
|
||
fmt.Println("default case")
|
||
}
|
||
|
||
Este programa mostra a seguinte informação.
|
||
|
||
integer <= 6
|
||
integer <= 7
|
||
integer <= 8
|
||
default case
|
||
|
||
## Funções
|
||
|
||
Use a palavra-chave `func` para definir uma função.
|
||
|
||
func funcName(input1 type1, input2 type2) (output1 type1, output2 type2) {
|
||
// corpo da função
|
||
// retorno de múltiplos valores
|
||
return value1, value2
|
||
}
|
||
|
||
Nós podemos extrapolar as seguintes informações do exemplo acima.
|
||
|
||
- Use a palavra-chave `func` para definir uma função `funcName`.
|
||
- Funções tem zero, um ou mais argumentos. O tipo do argumento vem depois do nome do argumento e vários argumentos são separados por `,`.
|
||
- Funções podem retornar múltiplos valores.
|
||
- Existem dois valores de retorno com os nomes `output1` e `output2`, você pode omitir estes nomes e usar apenas os tipos deles.
|
||
- Se existe apenas um valor de retorno e você omitir o nome, você não precisa usar colchetes nos valores de retorno.
|
||
- Se a função não possui valores de retorno, você pode omitir os parâmetros de retorno completamente.
|
||
- Se a função possui valores de retorno, você precisa utilizar a instrução `return` em algum lugar no corpo da função.
|
||
|
||
Vamos ver um exemplo prático. (calcular o valor máximo)
|
||
|
||
package main
|
||
import "fmt"
|
||
|
||
// retorna o maior valor entre a e b
|
||
func max(a, b int) int {
|
||
if a > b {
|
||
return a
|
||
}
|
||
return b
|
||
}
|
||
|
||
func main() {
|
||
x := 3
|
||
y := 4
|
||
z := 5
|
||
|
||
max_xy := max(x, y) // chama a função max(x, y)
|
||
max_xz := max(x, z) // chama a função max(x, z)
|
||
|
||
fmt.Printf("max(%d, %d) = %d\n", x, y, max_xy)
|
||
fmt.Printf("max(%d, %d) = %d\n", x, z, max_xz)
|
||
fmt.Printf("max(%d, %d) = %d\n", y, z, max(y,z)) // chama a função max aqui
|
||
}
|
||
|
||
No exemplo acima existem dois argumentos do tipo `int` na função `max`, sendo assim o tipo do primeiro argumento pode ser omitido. Por exemplo, pode-se utilizar `a, b int` em vez de `a int, b int`. As mesmas regras se aplicam para argumentos adicionais. Observe aqui que `max` só tem um valor de retorno, então nós só precisamos escrever o tipo do valor de retorno. Esta é a forma curta de escrevê-lo.
|
||
|
||
### Múltiplos valores de retorno
|
||
|
||
Uma coisa em que Go é melhor que C é que ela suporta múltiplos valores de retorno.
|
||
|
||
Usaremos o seguinte exemplo.
|
||
|
||
package main
|
||
import "fmt"
|
||
|
||
// Retorna os resultados de A + B e A * B
|
||
func SumAndProduct(A, B int) (int, int) {
|
||
return A+B, A*B
|
||
}
|
||
|
||
func main() {
|
||
x := 3
|
||
y := 4
|
||
|
||
xPLUSy, xTIMESy := SumAndProduct(x, y)
|
||
|
||
fmt.Printf("%d + %d = %d\n", x, y, xPLUSy)
|
||
fmt.Printf("%d * %d = %d\n", x, y, xTIMESy)
|
||
}
|
||
|
||
O exemplo acima retorna dois valores sem nomes - você também tem a opção de nomeá-los se preferir. Se nomearmos os valores de retorno, poderemos utilizar apenas a instrução `return` para retornar os valores já que eles foram inicializados na função automaticamente. Observe que se suas funções forem utilizadas fora do pacote, o que significa que o nome das funções começam com uma letra maiúscula, é melhor escrever instruções completas para o `return`. Isto torna o seu código mais legível.
|
||
|
||
func SumAndProduct(A, B int) (add int, Multiplied int) {
|
||
add = A+B
|
||
Multiplied = A*B
|
||
return
|
||
}
|
||
|
||
### Argumentos variáveis
|
||
|
||
Go suporta argumentos variáveis, o que significa que você pode dar um número incerto de argumentos para funções.
|
||
|
||
func myfunc(arg ...int) {}
|
||
|
||
A instrução `arg …int` significa que esta é uma função que possui argumentos variáveis. Observe que estes argumentos são do tipo `int`. No corpo da função o `arg` se torna um `slice` de `int`.
|
||
|
||
for _, n := range arg {
|
||
fmt.Printf("And the number is: %d\n", n)
|
||
}
|
||
|
||
### Passar por valor e ponteiros
|
||
|
||
Quando passamos um argumento para uma função que foi chamada, a função recebe na verdade uma cópia da nossa variáveis original, sendo assim, as alterações não afetarão a variável original.
|
||
|
||
Vejamos um exemplo para provar o que eu estou dizendo.
|
||
|
||
package main
|
||
import "fmt"
|
||
|
||
// Função simples que adiciona 1 a variável a
|
||
func add1(a int) int {
|
||
a = a+1 // alteramos o valor de a
|
||
return a // retornamos o novo valor de a
|
||
}
|
||
|
||
func main() {
|
||
x := 3
|
||
|
||
fmt.Println("x = ", x) // deve mostrar "x = 3"
|
||
|
||
x1 := add1(x) // chama add1(x)
|
||
|
||
fmt.Println("x+1 = ", x1) // deve mostrar "x+1 = 4"
|
||
fmt.Println("x = ", x) // deve mostrar "x = 3"
|
||
}
|
||
|
||
Você consegue ver isso? Mesmo que nós chamamos `add1` com `x`, o valor original de `x` não é alterado.
|
||
|
||
A razão é muito simples: quando chamamos `add1`, nós passamos uma cópia de `x` para a função, e não o próprio `x`.
|
||
|
||
Agora você pode se perguntar, como eu posso passar o `x` original para a função.
|
||
|
||
Precisamos usar ponteiros aqui. Sabemos que as variáveis são armazenadas em memória e que elas possuem endereços de memória. Então, se queremos alterar o valor de uma variável, precisamos alterar o valor armazenado no endereço de memória. Portanto, a função `add1` precisa saber o endereço de memória de `x` para poder alterar o seu valor. Para isto, passamos `&x` para a função, e alteramos o tipo do argumento para o tipo ponteiro `*int`. Esteja ciente de que nós passamos uma cópia do ponteiro, não uma cópia do valor.
|
||
|
||
package main
|
||
import "fmt"
|
||
|
||
// Função simples que adiciona 1 a variável a
|
||
func add1(a *int) int {
|
||
*a = *a+1 // alteramos o valor de a
|
||
return *a // retornamos o novo valor de a
|
||
}
|
||
|
||
func main() {
|
||
x := 3
|
||
|
||
fmt.Println("x = ", x) // deve mostrar "x = 3"
|
||
|
||
x1 := add1(&x) // call add1(&x) pass memory address of x
|
||
|
||
fmt.Println("x+1 = ", x1) // deve mostrar "x+1 = 4"
|
||
fmt.Println("x = ", x) // deve mostrar "x = 4"
|
||
}
|
||
|
||
Agora podemos alterar o valor de `x` dentro da função. Por que usamos ponteiros? Quais são as vantagens?
|
||
|
||
- Permite-nos usar mais funções para operar em uma variável.
|
||
- Baixo custo passando endereços de memória (8 bytes), a cópia não é uma maneira eficiente, tanto em termo de tempo como de espaço, para passar variáveis.
|
||
- `string`, `slice`, `map` são tipos de referências, sendo assim, por padrão eles utilizam ponteiros ao passar para uma função. (Atenção: Se você precisa alterar o comprimento de um `slice`, você precisa passar ponteiros explicitamente)
|
||
|
||
### defer
|
||
|
||
Go possui uma palavra-chave bem projetada chamada `defer`. Você pode ter muitas declarações `defer` em uma função. Elas serão executadas em ordem inversa quando o programa executa até o final das funções. No caso onde o programa abre alguns arquivos de recurso, estes arquivos precisam ser fechados antes que a função possa retornar com erros. Vamos ver alguns exemplos.
|
||
|
||
func ReadWrite() bool {
|
||
file.Open("file")
|
||
// Faça alguma tarefa
|
||
if failureX {
|
||
file.Close()
|
||
return false
|
||
}
|
||
|
||
if failureY {
|
||
file.Close()
|
||
return false
|
||
}
|
||
|
||
file.Close()
|
||
return true
|
||
}
|
||
|
||
Vimos algum código sendo repetido várias vezes. `defer` resolve este problema muito bem. Ela não só ajuda você a escrever um código limpo, como também torna seu código mais legível.
|
||
|
||
func ReadWrite() bool {
|
||
file.Open("file")
|
||
defer file.Close()
|
||
if failureX {
|
||
return false
|
||
}
|
||
if failureY {
|
||
return false
|
||
}
|
||
return true
|
||
}
|
||
|
||
Se houver mais de uma instrução `defer`, elas serão executadas em ordem inversa. O exemplo a seguir irá mostrar `4 3 2 1 0`.
|
||
|
||
for i := 0; i < 5; i++ {
|
||
defer fmt.Printf("%d ", i)
|
||
}
|
||
|
||
### Funções como tipos e valores
|
||
|
||
Funções também são variáveis em Go, podemos utilizar `type` para defini-las. Funções que possuem a mesma assinatura podem ser vistas como sendo do mesmo tipo.
|
||
|
||
type typeName func(input1 inputType1 , input2 inputType2 [, ...]) (result1 resultType1 [, ...])
|
||
|
||
Qual é a vantagem deste recurso? A resposta é que isto nos permite passar funções como valores.
|
||
|
||
package main
|
||
import "fmt"
|
||
|
||
type testInt func(int) bool // define o tipo de uma função como variável
|
||
|
||
func isOdd(integer int) bool {
|
||
if integer%2 == 0 {
|
||
return false
|
||
}
|
||
return true
|
||
}
|
||
|
||
func isEven(integer int) bool {
|
||
if integer%2 == 0 {
|
||
return true
|
||
}
|
||
return false
|
||
}
|
||
|
||
// passa a função `f` como um argumento para outra função
|
||
|
||
func filter(slice []int, f testInt) []int {
|
||
var result []int
|
||
for _, value := range slice {
|
||
if f(value) {
|
||
result = append(result, value)
|
||
}
|
||
}
|
||
return result
|
||
}
|
||
|
||
func main(){
|
||
slice := []int {1, 2, 3, 4, 5, 7}
|
||
fmt.Println("slice = ", slice)
|
||
odd := filter(slice, isOdd) // usa a função como valor
|
||
fmt.Println("Odd elements of slice are: ", odd)
|
||
even := filter(slice, isEven)
|
||
fmt.Println("Even elements of slice are: ", even)
|
||
}
|
||
|
||
Isto é muito útil quando utilizamos interfaces. Como você pode ver `testInt` é uma variável que tem tipo de função, e os valores de retorno e argumentos de `filter` são os mesmos de `testInt`. Portanto, podemos ter lógica complexa em nossos programas mantendo a flexibilidade em nosso código.
|
||
|
||
### Panic e Recover
|
||
|
||
Go não possui a estrutura `try-catch` assim como Java. Em vez de lançar exceções, Go usa `panic` e `recover` para lidar com erros. No entanto, embora poderoso, você não deve utilizar a instrução `panic` muito.
|
||
|
||
Panic é uma função interna para quebrar o fluxo normal de programas e entrar em estado de pânico. Quando uma função `F` chama `panic`, `F` não continuará executando, mas suas funções `defer` continuarão a ser executadas. Então `F` volta ao ponto de interrupção que causou o estado de pânico. O programa não terminará até que todas essas funções retornem com panic para o primeiro nível da `goroutine`. `panic` pode ser gerado executando a instrução `panic` no programa, e alguns erros também causam `panic`, como, por exemplo, a tentativa de acessar uma posição inválida em um array.
|
||
|
||
Recover é uma função interna utilizada para recuperar goroutines de estados de pânico. Chamar `recover` nas funções `defer` é útil porque as funções normais não serão executadas quando o programa estiver em estado de pânico. Ele recebe os valores de `panic` se o programa está em estado de pânico, e recebe `nil` se o programa não está em estado de pânico.
|
||
|
||
O seguinte exemplo mostra como utilizar `panic`.
|
||
|
||
var user = os.Getenv("USER")
|
||
|
||
func init() {
|
||
if user == "" {
|
||
panic("no value for $USER")
|
||
}
|
||
}
|
||
|
||
O seguinte exemplo mostra como verificar `panic`.
|
||
|
||
func throwsPanic(f func()) (b bool) {
|
||
defer func() {
|
||
if x := recover(); x != nil {
|
||
b = true
|
||
}
|
||
}()
|
||
f() // se f causar pânico, ele irá recuperar
|
||
return
|
||
}
|
||
|
||
### Função `main` e função `init`
|
||
|
||
Go possui duas retenções que são chamadas de `main` e `init`, onde `init` pode ser usada em todos os pacotes e `main` só pode ser usada no pacote `main`. Estas duas funções não são capazes de ter argumentos ou valores de retorno. Mesmo que possamos escrever muitas funções `init` em um pacote, recomendo fortemente escrever apenas uma função `init` para cada pacote.
|
||
|
||
Programas em Go irão chamar as funções `init()` e `main()` automaticamente, então você não precisa se preocupar em chamá-las. Para cada pacote, a função `init` é opcional, mas o `package main` tem uma e apenas uma função `main`.
|
||
|
||
Programas inicializam e começam a execução a partir do pacote `main`. Se o pacote `main` importa outros pacotes, eles serão importados em tempo de compilação. Se um pacote é importado muitas vezes, ele será compilado apenas uma vez. Depois de importar pacotes, os programas irão inicializar as constantes e variáveis dentro dos pacotes importados, e então executar a função `init` se ela existir, e assim por diante. Depois de todos os outros pacotes serem inicializados, os programas irão inicializar as constantes e variáveis do pacote `main` e então executar a função `init` dentro do pacote, se ela existir. A figura a seguir mostra o processo.
|
||
|
||
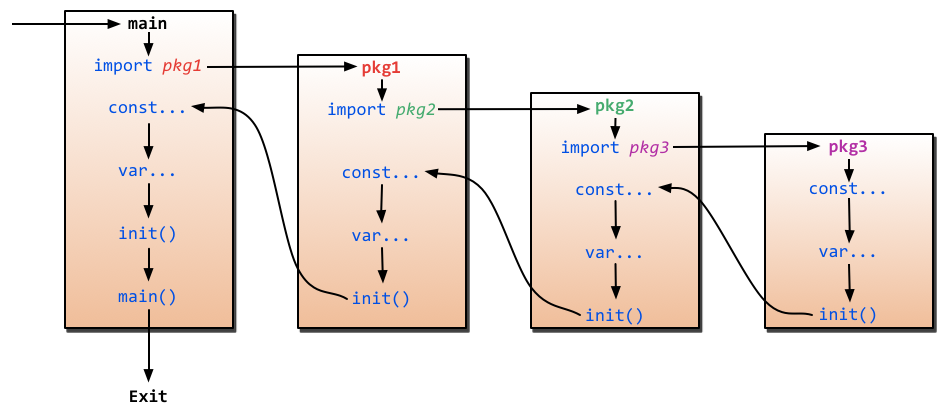
|
||
|
||
Figure 2.6 Fluxo de inicialização de programas em Go
|
||
|
||
### import
|
||
|
||
Usamos `import` muito frequentemente em programas Go da seguinte forma.
|
||
|
||
import(
|
||
"fmt"
|
||
)
|
||
|
||
Então, usamos funções deste pacote da seguinte maneira.
|
||
|
||
fmt.Println("hello world")
|
||
|
||
`fmt` é da biblioteca padrão Go, que está localizada em $GOROOT/pkg. Go suporta pacotes de terceiros de duas maneiras.
|
||
|
||
1. Caminho relativo
|
||
import "./model" // carrega o pacote no mesmo diretório, eu não recomendo utilizar esta forma.
|
||
2. Caminho absoluto
|
||
import "shorturl/model" // carrega o pacote no caminho "$GOPATH/pkg/shorturl/model"
|
||
|
||
Existem alguns operadores especiais quando importamos pacotes, e iniciantes na linguagem sempre se confundem com estes operadores.
|
||
|
||
1. Operador: ponto.
|
||
Às vezes vemos pessoas usando a seguinte forma para importar pacotes.
|
||
|
||
import(
|
||
. "fmt"
|
||
)
|
||
|
||
O operador ponto significa que você pode omitir o nome do pacote quando você chamar funções dentro deste pacote. Assim sendo, `fmt.Printf("Hello world")` torna-se `Printf("Hello world")`.
|
||
2. Operador: pseudônimo (alias)
|
||
Ele altera o nome do pacote que importamos quando chamamos funções que pertencem a este pacote.
|
||
|
||
import(
|
||
f "fmt"
|
||
)
|
||
|
||
Assim sendo, `fmt.Printf("Hello world")` torna-se `f.Printf("Hello world")`.
|
||
3. Operador: `_`.
|
||
Este operador é difícil de entender sem alguém explicando para você.
|
||
|
||
import (
|
||
"database/sql"
|
||
_ "github.com/ziutek/mymysql/godrv"
|
||
)
|
||
|
||
O operador `_` na verdade significa que só queremos importar este pacote e executar sua função `init`, e não temos certeza se queremos usar as funções pertencentes a este pacote.
|
||
|
||
## Links
|
||
|
||
- [Sumário](preface.md)
|
||
- Seção anterior: [Fundamentos em Go](02.2.md)
|
||
- Próxima seção: [struct](02.4.md)
|