156 lines
12 KiB
Markdown
156 lines
12 KiB
Markdown
# Principios da Web
|
||
|
||
Toda vez que você abrir seus navegadores, digite alguns URLs e pressione enter, você verá lindas páginas da web aparecerem na tela. Mas você sabe o que está acontecendo por trás dessas ações simples?
|
||
|
||
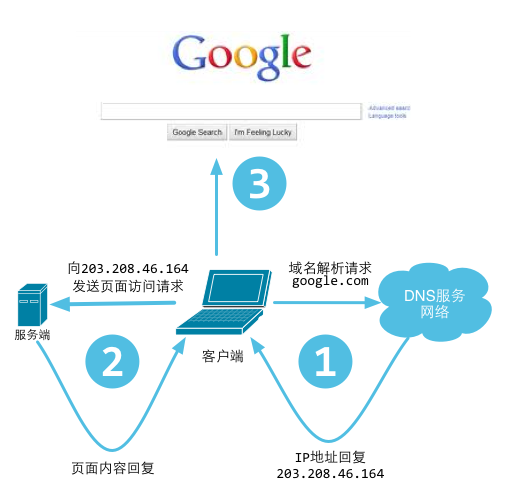
Normalmente, seu navegador é um cliente. Depois de digitar um URL, ele pega a parte do host do URL e a envia para um servidor DNS para obter o endereço IP do host. Em seguida, ele se conecta ao endereço IP e solicita a configuração de uma conexão TCP. O navegador envia solicitações HTTP por meio da conexão. O servidor lida com eles e responde com respostas HTTP contendo o conteúdo que compõe a página da web. Por fim, o navegador renderiza o corpo da página da Web e se desconecta do servidor.
|
||
|
||
|
||
|
||
Imagem: 3.1 Processo dos usuários visitando um site
|
||
|
||
Um servidor da Web, também conhecido como servidor HTTP, usa o protocolo HTTP para se comunicar com os clientes. Todos os navegadores da web podem ser considerados clientes.
|
||
|
||
Podemos dividir os princípios de trabalho da Web nas seguintes etapas:
|
||
|
||
- Cliente usa o protocolo TCP / IP para se conectar ao servidor.
|
||
- Cliente envia pacotes de solicitações HTTP para o servidor.
|
||
- O servidor retorna pacotes de resposta HTTP ao cliente. Se os recursos solicitados incluírem scripts dinâmicos, o mecanismo de script de chamadas do servidor será o primeiro.
|
||
- Cliente se desconecta do servidor, começa a renderizar HTML.
|
||
|
||
Este é um fluxo de trabalho simples de assuntos HTTP - observe que o servidor fecha suas conexões depois de enviar dados para os clientes e aguarda a próxima solicitação.
|
||
|
||
## Resolvendo URL e DNS
|
||
|
||
Nós sempre usamos URLs para acessar páginas da web, mas você sabe como funcionam os URLs?
|
||
|
||
O nome completo de uma URL é Uniform Resource Locator. É para descrever recursos na internet e sua forma básica é a seguinte.
|
||
|
||
scheme://host[:port#]/path/.../[?query-string][#anchor]
|
||
scheme Define o protocolo a ser utilizado (Ex: HTTP, HTTPS, FTP)
|
||
host IP ou nome do domínino do servidor HTTP
|
||
port# a porta padrão é 80 e pode ser omitida nesse caso. Se você quiser usar outras portas, você deve especificar qual porta. Por exemplo, http://www.cnblogs.com:8080/
|
||
path Caminho
|
||
query-string Dados enviados através da URI
|
||
anchor Âncora
|
||
|
||
DNS é uma abreviação de Domain Name System. É o sistema de nomes para serviços de rede de computadores e converte nomes de domínio em endereços IP reais, exatamente como um tradutor.
|
||
|
||

|
||
|
||
Imagem 3.2 Principios do DNS
|
||
|
||
Para entender mais sobre seu princípio de funcionamento, vamos ver o processo detalhado de resolução de DNS como segue.
|
||
|
||
1. Depois de digitar o nome de domínio `www.qq.com` no navegador, o sistema operacional verificará se há algum relacionamento de mapeamento nos arquivos dos hosts para este nome de domínio. Em caso afirmativo, a resolução do nome de domínio será concluída.
|
||
2. Se não existirem relacionamentos de mapeamento nos arquivos dos hosts, o sistema operacional verificará se existe algum cache no DNS. Em caso afirmativo, a resolução do nome de domínio será concluída.
|
||
3. Se não existirem relações de mapeamento no host e no cache DNS, o sistema operacional localizará o primeiro servidor de resolução de DNS nas configurações de TCP / IP, o que provavelmente é o servidor DNS local. Quando o servidor DNS local recebe a consulta, se o nome de domínio que você deseja consultar estiver contido na configuração local de seus recursos regionais, ele retornará os resultados para o cliente. Essa resolução de DNS é autoritativa.
|
||
4. Se o servidor DNS local não contiver o nome de domínio, mas existir um relacionamento de mapeamento no cache, o servidor DNS local devolverá esse resultado ao cliente. Essa resolução de DNS não é autoritativa.
|
||
5. Se o servidor DNS local não puder resolver esse nome de domínio por meio da configuração de recursos regionais ou do cache, ele prosseguirá para a próxima etapa, que depende das configurações do servidor DNS local.
|
||
- Se o servidor DNS local não habilitar o encaminhamento, ele encaminhará a solicitação para o servidor DNS raiz e, em seguida, retornará o endereço IP de um servidor DNS de nível superior que pode saber o nome do domínio, `.com` neste caso. Se o primeiro servidor DNS de nível superior não reconhecer o nome de domínio, ele redireciona novamente a solicitação para o próximo servidor DNS de nível superior até que ele atinja um que reconheça o nome do domínio. Em seguida, o servidor DNS de nível superior solicita a este servidor DNS de nível seguinte o endereço IP correspondente a `www.qq.com`.
|
||
-Se o servidor DNS local tiver o encaminhamento ativado, ele enviará a solicitação para um servidor DNS de nível superior. Se o servidor DNS de nível superior também não reconhecer o nome de domínio, a solicitação continuará sendo reencaminhada para níveis mais altos até que finalmente chegue a um servidor DNS que reconheça o nome do domínio.
|
||
|
||
Independentemente de o servidor DNS local permitir ou não o encaminhamento, o endereço IP do nome de domínio sempre retornará ao servidor DNS local e o servidor DNS local o enviará de volta ao cliente.
|
||
|
||

|
||
|
||
Imagem 3.3 Caminhos do fluxo DNS
|
||
|
||
`Processo de consulta recursiva` significa simplesmente que os inquiridores mudam no processo. Os inquiridores não mudam nos processos de consulta iterativa.
|
||
|
||
Agora sabemos que os clientes obtêm endereços IP no final, portanto, os navegadores estão se comunicando com servidores por meio de endereços IP.
|
||
|
||
## Protocolo HTTP
|
||
|
||
O protocolo HTTP é uma parte essencial dos serviços da web. É importante saber o que é o protocolo HTTP antes de entender como a Web funciona.
|
||
|
||
HTTP é o protocolo usado para facilitar a comunicação entre navegadores e servidores da web. Ele é baseado no protocolo TCP e geralmente usa a porta 80 no lado do servidor da web. É um protocolo que utiliza o modelo de solicitação-resposta - os clientes enviam solicitações e os servidores respondem. De acordo com o protocolo HTTP, os clientes sempre configuram novas conexões e enviam solicitações HTTP para os servidores. Os servidores não podem se conectar aos clientes de maneira proativa ou estabelecer conexões de retorno de chamada. A conexão entre um cliente e um servidor pode ser fechada por qualquer um dos lados. Por exemplo, você pode cancelar sua solicitação de download e a conexão HTTP e seu navegador desconectará do servidor antes de concluir o download.
|
||
|
||
O protocolo HTTP é sem estado, o que significa que o servidor não tem idéia sobre o relacionamento entre as duas conexões, embora sejam do mesmo cliente. Para resolver esse problema, os aplicativos da Web usam cookies para manter o estado das conexões.
|
||
|
||
Como o protocolo HTTP é baseado no protocolo TCP, todos os ataques TCP afetarão as comunicações HTTP em seu servidor. Exemplos de tais ataques são inundações SYN, ataques DoS e DDoS.
|
||
|
||
### Pacote de request HTTP (informação do browser)
|
||
|
||
Todos os pacotes de solicitação têm três partes: linha de solicitação, cabeçalho de solicitação e corpo. Há uma linha em branco entre o cabeçalho e o corpo.
|
||
|
||
GET /domains/example/ HTTP/1.1 // request line: request method, URL, protocol and its version
|
||
Host:www.iana.org // domain name
|
||
User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4 // browser information
|
||
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 // mime that clients can accept
|
||
Accept-Encoding:gzip,deflate,sdch // stream compression
|
||
Accept-Charset:UTF-8,*;q=0.5 // character set in client side
|
||
// blank line
|
||
// body, request resource arguments (for example, arguments in POST)
|
||
|
||
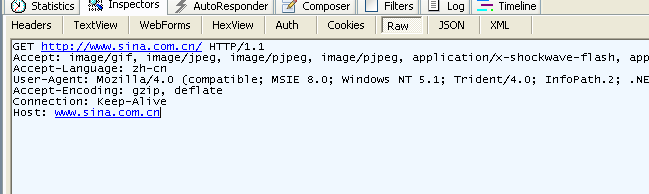
Usamos fiddler para obter as seguintes informações de solicitação.
|
||
|
||
|
||
|
||
Imagem 3.4 Informação de um GET request mostrado pelo fiddler
|
||
|
||
|
||
|
||
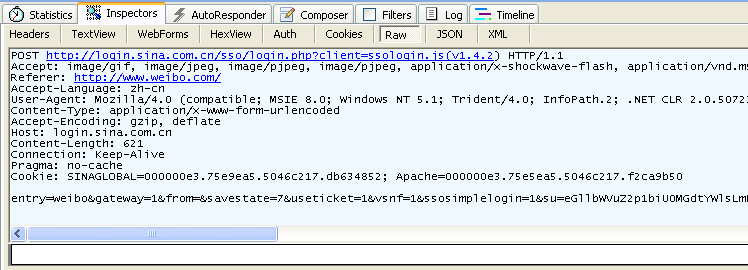
Imagem 3.5 Informação de um POST request mostrado pelo fiddler
|
||
|
||
**We can see that GET does not have a request body, unlike POST, which does.**
|
||
|
||
** Podemos ver que o GET não tem um corpo de solicitação, ao contrário do POST, que faz. **
|
||
|
||
Existem muitos métodos que você pode usar para se comunicar com servidores em HTTP; GET, POST, PUT e DELETE são os 4 métodos básicos que normalmente usamos. Uma URL representa um recurso em uma rede, portanto, esses quatro métodos definem a consulta, alteram, adicionam e excluem operações que podem atuar nesses recursos. GET e POST são muito usados em HTTP. GET pode anexar parâmetros de consulta à URL, usando `?` Para separar a URL e os parâmetros e `&` entre os argumentos, como `EditPosts.aspx?name=test1&id=123456`. O POST coloca dados no corpo da solicitação porque o URL implementa uma limitação de tamanho por meio do navegador. Assim, o POST pode enviar muito mais dados do que o GET. Além disso, quando enviamos nomes de usuário e senhas, não queremos que esse tipo de informação apareça no URL. Por isso, usamos o POST para mantê-los invisíveis.
|
||
|
||
### HTTP response package (informação do servidor)
|
||
|
||
Vamos ver quais informações estão contidas nos pacotes de resposta.
|
||
|
||
HTTP/1.1 200 OK // status line
|
||
Server: nginx/1.0.8 // web server software and its version in the server machine
|
||
Date:Date: Tue, 30 Oct 2012 04:14:25 GMT // responded time
|
||
Content-Type: text/html // responded data type
|
||
Transfer-Encoding: chunked // it means data were sent in fragments
|
||
Connection: keep-alive // keep connection
|
||
Content-Length: 90 // length of body
|
||
// blank line
|
||
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"... // message body
|
||
|
||
A primeira linha é chamada de linha de status. Ele fornece a versão HTTP, o código de status e a mensagem de status.
|
||
|
||
O código de status informa ao cliente o status da resposta do servidor HTTP. No HTTP / 1.1, 5 tipos de códigos de status foram definidos:
|
||
|
||
- 1xx Informação
|
||
- 2xx Sucesso
|
||
- 3xx Redirecionamento
|
||
- 4xx Erro ao lado Cliente(ex: 404)
|
||
- 5xx Erro ao lado do servidor (ex: 502)
|
||
|
||
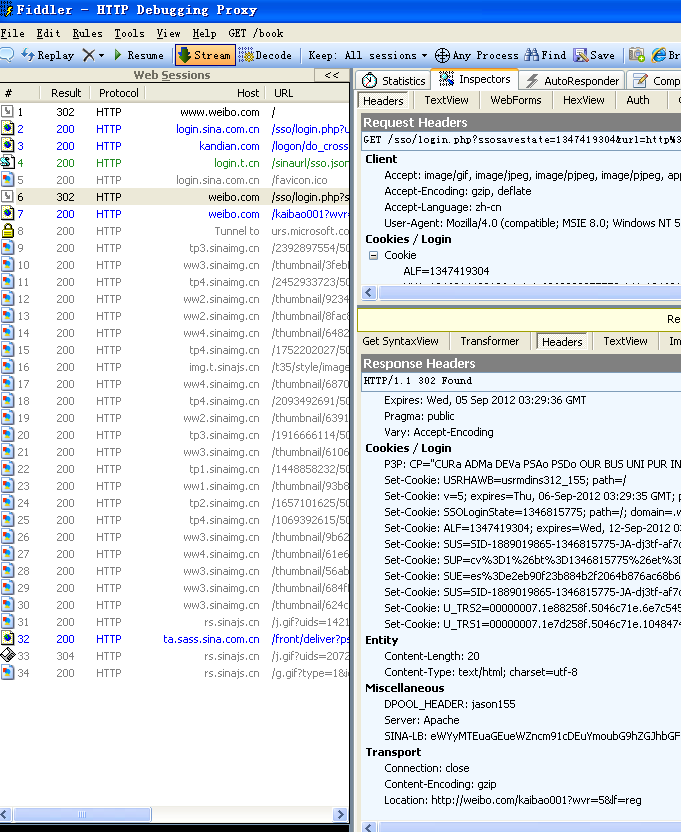
Vamos ver mais exemplos sobre pacotes de resposta. 200 significa que o servidor respondeu corretamente, 302 significa redirecionamento.
|
||
|
||
|
||
|
||
Imagem 3.6 Informação completa de um site
|
||
|
||
### HTTP é stateless e conexão: keep-alive
|
||
|
||
O termo stateless não significa que o servidor não tenha capacidade de manter uma conexão. Significa simplesmente que o servidor não reconhece nenhum relacionamento entre duas solicitações.
|
||
|
||
No HTTP / 1.1, o Keep-alive é usado por padrão. Se os clientes tiverem solicitações adicionais, eles usarão a mesma conexão para eles.
|
||
|
||
Observe que o Keep-alive não pode manter uma conexão para sempre; o aplicativo em execução no servidor determina o limite com o qual manter a conexão ativa e, na maioria dos casos, você pode configurar esse limite.
|
||
|
||
## Instancia de requisição
|
||
|
||

|
||
|
||
Imagem 3.7 Todos os pacotes
|
||
|
||
Podemos ver todo o processo de comunicação entre cliente e servidor da figura acima. Você pode perceber que há muitos arquivos de recursos na lista; esses são chamados de arquivos estáticos e o Go especializou-se em métodos de processamento para esses arquivos.
|
||
|
||
Essa é a função mais importante dos navegadores: solicitar uma URL e recuperar dados de servidores da Web e renderizar o HTML. Se encontrar alguns arquivos no DOM, como arquivos CSS ou JS, os navegadores solicitarão esses recursos do servidor novamente até que todos os recursos concluam a renderização na tela.
|
||
|
||
Reduzir os tempos de solicitação de HTTP é uma maneira de melhorar a velocidade de carregamento de páginas da web. Ao reduzir o número de arquivos CSS e JS que precisam ser carregados, as latências de solicitação e a pressão nos servidores da Web podem ser reduzidas ao mesmo tempo.
|
||
|
||
## Links
|
||
|
||
- [Sumário](preface.md)
|
||
- Seção anterior: [Fundamentos da Web](03.0.md)
|
||
- Próxima seção: [Construindo um servidor web simples](03.2.md)
|